
DeepSeek V4下周登场,美股再次颤抖!「跳过」英伟达,便宜50倍
DeepSeek V4下周登场,美股再次颤抖!「跳过」英伟达,便宜50倍DeepSeek V4下周登场:原生多模态,绕过英伟达,针对国产芯片深度优化。华尔街最怕的那条逻辑可能又要重演:算力霸权松动,美股先颤抖。
来自主题: AI资讯
9498 点击 2026-03-01 16:38
 搜索
搜索
DeepSeek V4下周登场:原生多模态,绕过英伟达,针对国产芯片深度优化。华尔街最怕的那条逻辑可能又要重演:算力霸权松动,美股先颤抖。

所有人都在等 DeepSeek,春节来,下周来,还是没来。 一场为了全面「狙击」 DeepSeek,抢夺流量,但是 DeepSeek 都没出现的春节大战,就在一轮又一轮的红包奶茶里轰轰烈烈地结束了。
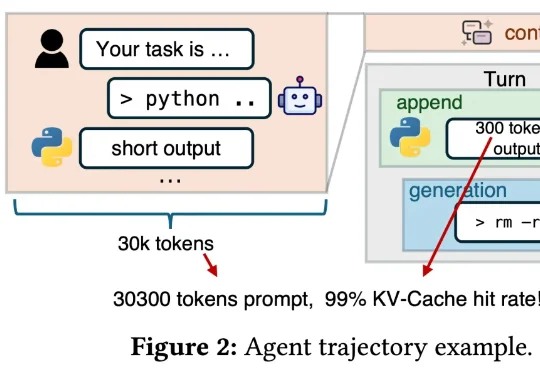
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。

最近,炸裂消息一个接一个。首先,DeepSeek V4将在一周内上线。第二,它跳过英伟达,把访问权限首先给了某国内芯片厂商。另外,Anthropic因为蒸馏事件,也被群嘲了。

科技账号 Legit 率先披露,V4 的轻量版本代号为「sealion-lite(海狮轻量版)」,目前已在至少一家推理服务商处展开内测,相关方均签署了严格的保密协议。

机器之心编译 如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。 自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在
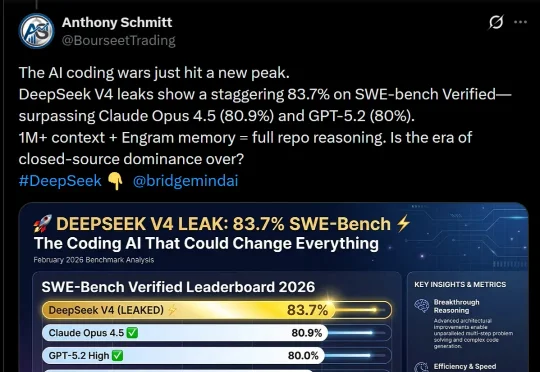
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!

确认了!DeepSeek昨晚官宣网页版、APP更新,支持100k token上下文。如今,全网都在蹲DeepSeek V4了。
这两天 AI 圈真的太热闹了,就在网传 DeepSeek 要更新支持 100 万 Token 上下文的新模型时,MiniMax 率先冲锋,更新了他们的新旗舰模型:MiniMax-M2.5。更有意思的是,国外网友这段时间对国内 AI 大模型的更新节奏格外关注,他们甚至把这种争先更新的现象称为:Happy Chinese new year!
春节还没到,「过年的气氛」已经渗入科技圈每个人的毛孔。单说 AI 大模型这一块,刚刚发布的有 kimi 2.5 和 Step 3.5 Flash,即将发布的据说还有 DeepSeek V4,GPT-5.3、Claude Sonnet 5、Qwen 3.5,GLM-5,说不定一觉醒来,现有的技术就要被颠覆。